
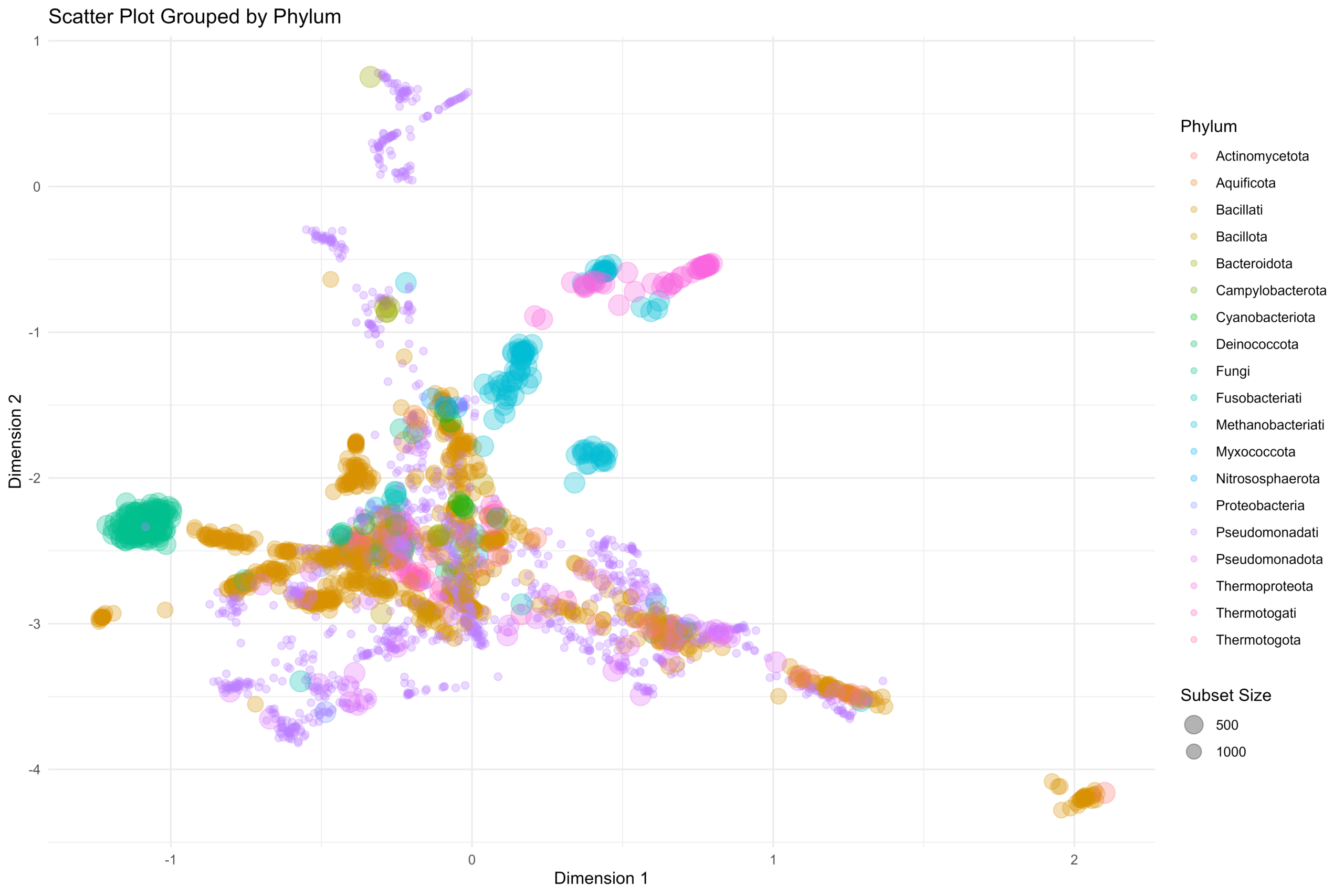
基因组
为了能够实现上面所描述的这种基于EC Number的不同层级的加权嵌入,我们在原来的基因组嵌入工具上添加了一个hierarchical选项,用于支持切换为层级嵌入的操作:
Imports Microsoft.VisualBasic.Data.Framework
Imports Microsoft.VisualBasic.Data.NLP
Imports SMRUCC.genomics.Interops.NCBI.Extensions.Pipeline
Public Class GenomeMetabolicEmbedding
ReadOnly vec As New TFIDF
ReadOnly taxonomy As New Dictionary(Of String, String)
ReadOnly hierarchical As Boolean = False
Sub New(Optional hierarchical As Boolean = False)
Me.hierarchical = hierarchical
End Sub
Public Sub Add(genome As GenomeVector)
If hierarchical Then
Call vec.Add(genome.assembly_id, genome.GetHierarchicalECNumberTerms)
Else
Call vec.Add(genome.assembly_id, genome.terms)
End If
Call taxonomy.Add(genome.assembly_id, genome.taxonomy)
End Sub
Public Function AddGenomes(seqs As IEnumerable(Of GenomeVector)) As GenomeMetabolicEmbedding
For Each annotation As GenomeVector In seqs
Call Add(annotation)
Next
Return Me
End Function
Public Function TfidfVectorizer(Optional normalize As Boolean = False) As DataFrame
Call $"Make metabolic embedding with: ".info
Call $" * {vec.N} genomes".debug
Call $" * {vec.Words.Length} total enzyme terms".debug
Call VBDebugger.EchoLine("")
Dim df As DataFrame = vec.TfidfVectorizer(normalize)
Call df.add("taxonomy", From id As String In df.rownames Select taxonomy(id))
Return df
End Function
''' <summary>
''' n-gram One-hot(Bag-of-n-grams)
''' </summary>
''' <returns></returns>
Public Function OneHotVectorizer() As DataFrame
Return vec.OneHotVectorizer
End Function
End Class在上面的模块中,会调用下面的函数来生成针对EC Number的层级嵌入结果:
''' <summary>
''' used for processing of the ec number terms, make the count of the
''' hierarchical ec number terms by summing the count of the specific
''' ec number terms
''' </summary>
''' <returns></returns>
Public Function GetHierarchicalECNumberTerms() As Dictionary(Of String, Integer)
Dim hierarchical As New Dictionary(Of String, Integer)
For Each ec_number As KeyValuePair(Of String, Integer) In terms.SafeQuery
Dim ec As ECNumber = ECNumber.ValueParser(ec_number.Key)
For Each ec_term As String In ec.HierarchicalECTerms
If Not hierarchical.ContainsKey(ec_term) Then
hierarchical(ec_term) = ec_number.Value
Else
hierarchical(ec_term) += ec_number.Value
End If
Next
Next
Return hierarchical
End Function对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。
基于上面的层级数据,我们仍然是将其输入TF-IDF算法模块中进行向量化嵌入
高级数据科学家 at 苏州帕诺米克
Working on Engineered bacteria CAD design on its genome from scratch. Writing scientific computing software for Tianhe & Sunway TaihuLight supercomputer. Do scientific computing programming in R/R# language, he is also the programming language designer of the R# language on the .NET runtime.
Latest posts by 谢桂纲 (see all)
- 基因组代谢酶层级嵌入 - 2026年2月23日
- 吉布斯LDA主题分解 - 2026年2月23日
- 酶EC编号结构解析 - 2026年2月17日

No responses yet