
估计阅读时长: 5 分钟基因组 为了能够实现上面所描述的这种基于EC Number的不同层级的加权嵌入,我们在原来的基因组嵌入工具上添加了一个hierarchical选项,用于支持切换为层级嵌入的操作: Imports Microsoft.VisualBasic.Data.Framework Imports Microsoft.VisualBasic.Data.NLP Imports SMRUCC.genomics.Interops.NCBI.Extensions.Pipeline Public Class GenomeMetabolicEmbedding ReadOnly vec As New […]

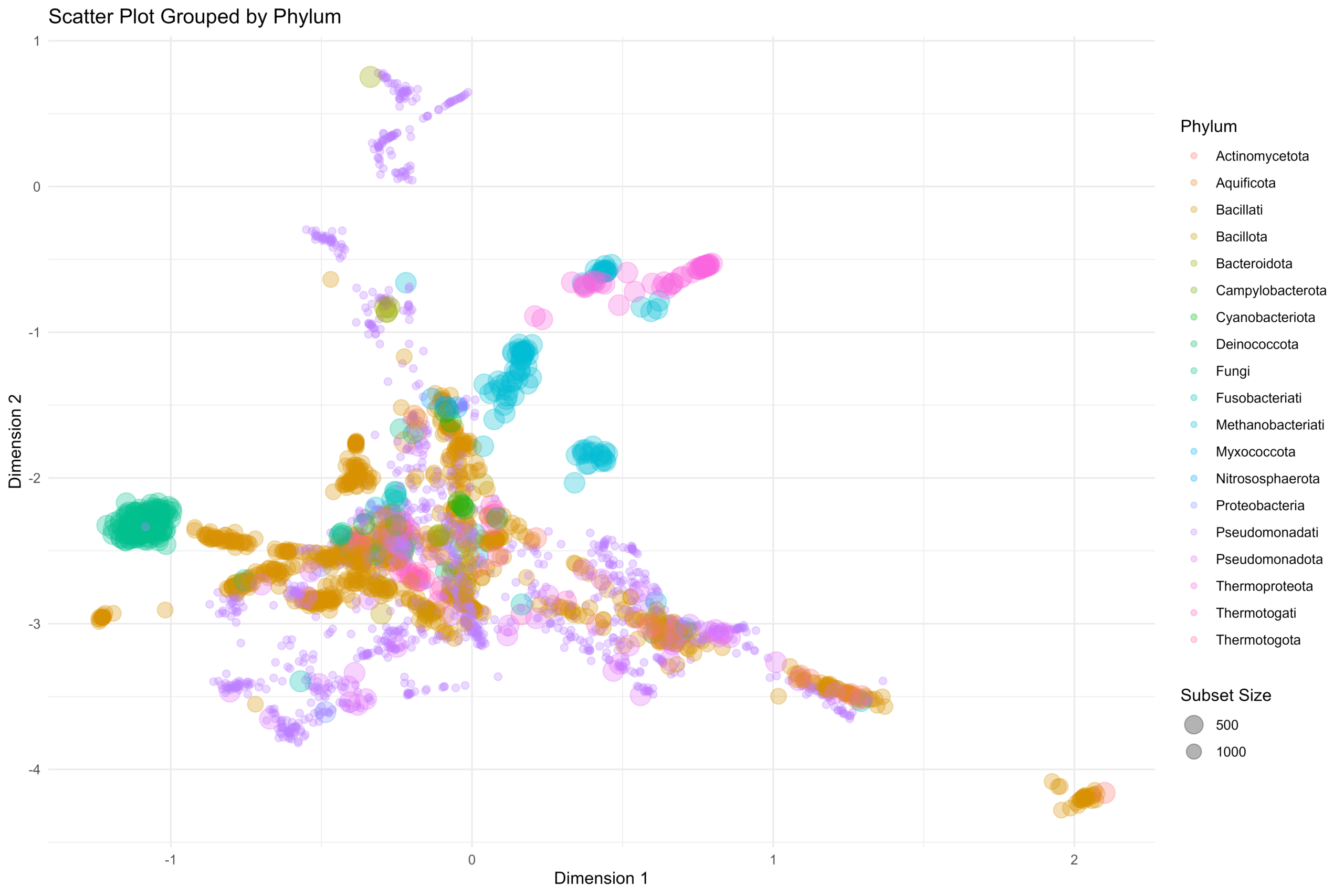
估计阅读时长: 18 分钟在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。除了针对降维后的数据进行散点图可视化,我们还可以直接针对向量化嵌入后的原始嵌入矩阵进行聚类,完成聚类结果的可视化。在这里我们主要是基于嵌入的原始结果进行二叉树聚类可视化。 Order by Date Name Attachments community_metabolic_tree • 220 kB • 77 click 2026年2月15日community-local • […]

估计阅读时长: 14 分钟宏基因组测序所处理的对象是直接对环境样本中的所有DNA进行测序。达到无需培养即可揭示微生物群落的组成和功能潜力的目的。在数据处理中,一个核心任务是从海量短读序列中估算物种丰度(即每个物种在样本中的相对含量)和基因丰度(即每个基因或功能单元的相对含量)。传统的基于序列比对的方法计算成本高昂,而基于k-mer的方法通过利用固定长度的子序列(k-mer)信息,能够在不依赖完整比对的情况下快速估算丰度。 k-mer是指长度为k的连续子序列,例如在k=2的时候,DNA序列“ATCG”包含的2-mers有“AT”、“TC”、“CG”。通过统计读序列中k-mer的出现频率,并将其与参考数据库中的k-mer频率进行比较,我们可以推断出样本中各物种或基因的丰度。这种方法具有计算速度快、内存效率高的优势,并且无需对每个读进行精确比对,因此在处理大规模宏基因组数据时非常实用。 Order by Date Name Attachments workflow1 • 272 kB • 206 click 2025年12月8日workflow2 • […]
估计阅读时长: 13 分钟LCA算法是现代宏基因组学分析的核心技术之一,主要用于解决序列比对结果的分类不确定性问题。例如,我们在处理宏基因组测序reads的物种来源分类注释工作的时候,经常会思考一个问题:在宏基因组分析中,一个测序read通常与多个参考序列产生比对结果,这些结果可能指向不同的分类单元。那这条reads最可能的物种分类来源位置是怎样的,怎样可以通过一个算法,基于一系列的物种匹配结果来推断出一个合适的物种来源,既避免过度分类,又保证分类的准确性。 Order by Date Name Attachments family-tree-animal-kingdom • 99 kB • 275 click 2025年12月2日LCA • 245 […]
估计阅读时长: 2 分钟宏基因组学(Metagenomics)通过直接测序环境样本中的全部DNA,从而避免了传统培养方法的局限,使我们能够研究不可培养微生物的多样性。然而,当样本来自宿主相关环境(如人类或小鼠的肠道、土壤等)时,测序数据中不可避免地包含大量宿主自身的DNA序列。这些宿主序列会占据测序读数,增加分析成本,并可能干扰对微生物群落组成的准确推断。因此,在宏基因组数据分析中,去除宿主序列(Host Sequence Removal)是至关重要的预处理步骤。去除宿主序列的算法多种多样,其中基于k-mer的方法因其高效和可扩展性而备受关注。 Attachments Metagenomics • 211 kB • 253 click 2025年11月29日

[…] 对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。 […]
[…] 在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。 […]
😲啊?
谢老师,写快点呀,在看着你更新文章呢。
[…] 最近的工作中我需要按照之前的这篇博客文章《基因组功能注释(EC Number)的向量化嵌入》中所描述的流程,将好几十万个微生物基因组的功能蛋白进行酶编号的比对注释,然后基于注释结果进行向量化嵌入然后进行数据可视化。通过R#脚本对这些微生物基因组的蛋白fasta序列的提取操作,最终得到了一个大约是58GB的蛋白序列。然后将这个比较大型的蛋白序列比对到自己所收集到的ec number注释的蛋白序列参考数据库之上。 […]