
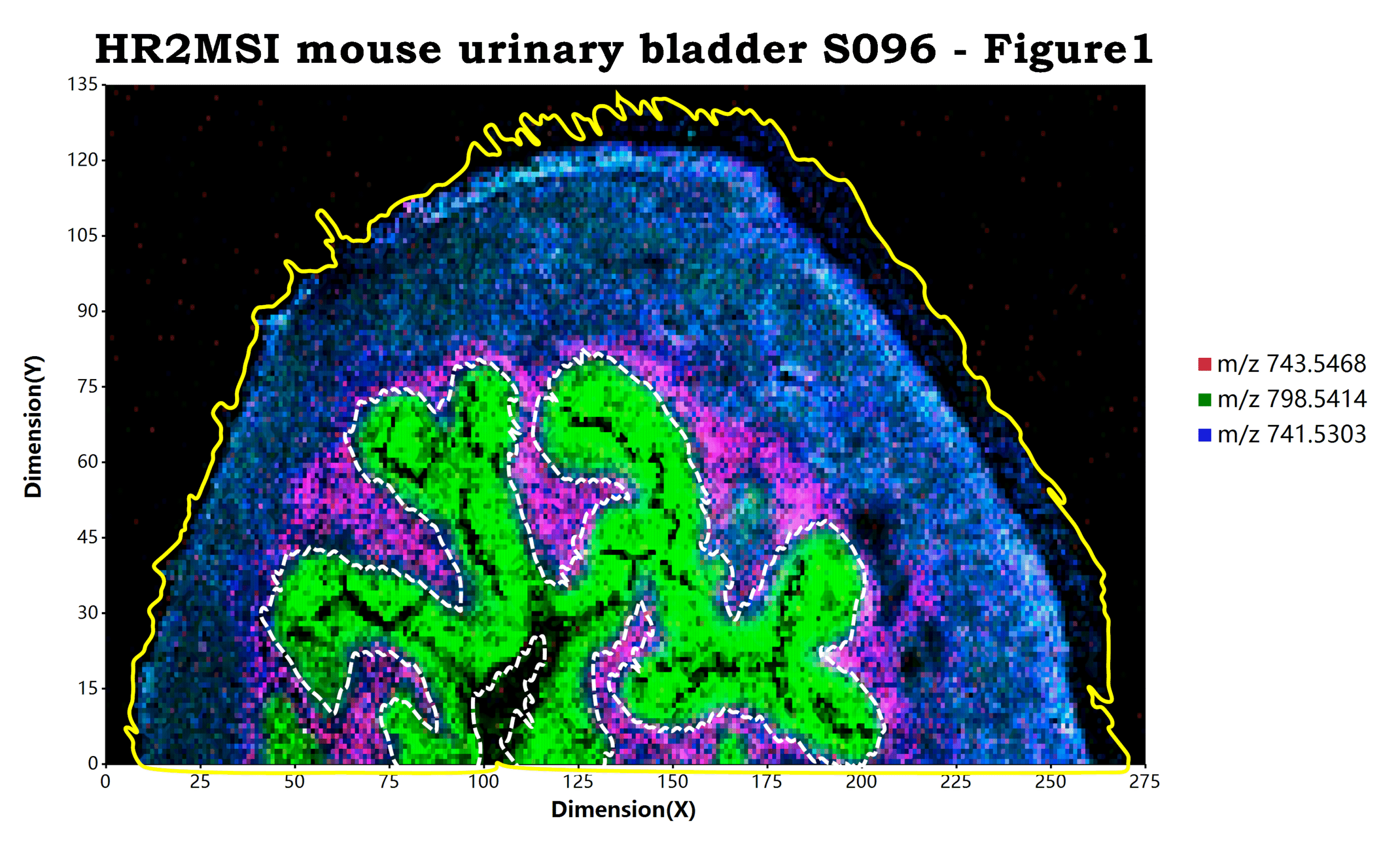
估计阅读时长: 10 分钟目前经过改进和优化之后的基于mzkit代码库底层的msimaging质谱成像软件包在样本可视化上进行了非常多的改进,诸如: 添加样本原始背景叠加 目前进行质谱成像可视化,程序包不仅仅可以使用任意rgb纯色来作为可视化的背景。目前还可以支持直接使用原始数据的背景作为质谱成像的显示背景。进行这个显示的秘诀就在于简单的在脚本中添加一个TIC背景图层:geom_MSIbackground("TIC") ggplot(msi_data, padding = "padding: 200px 600px 200px 250px;") + geom_MSIbackground("TIC") # rendering of […]
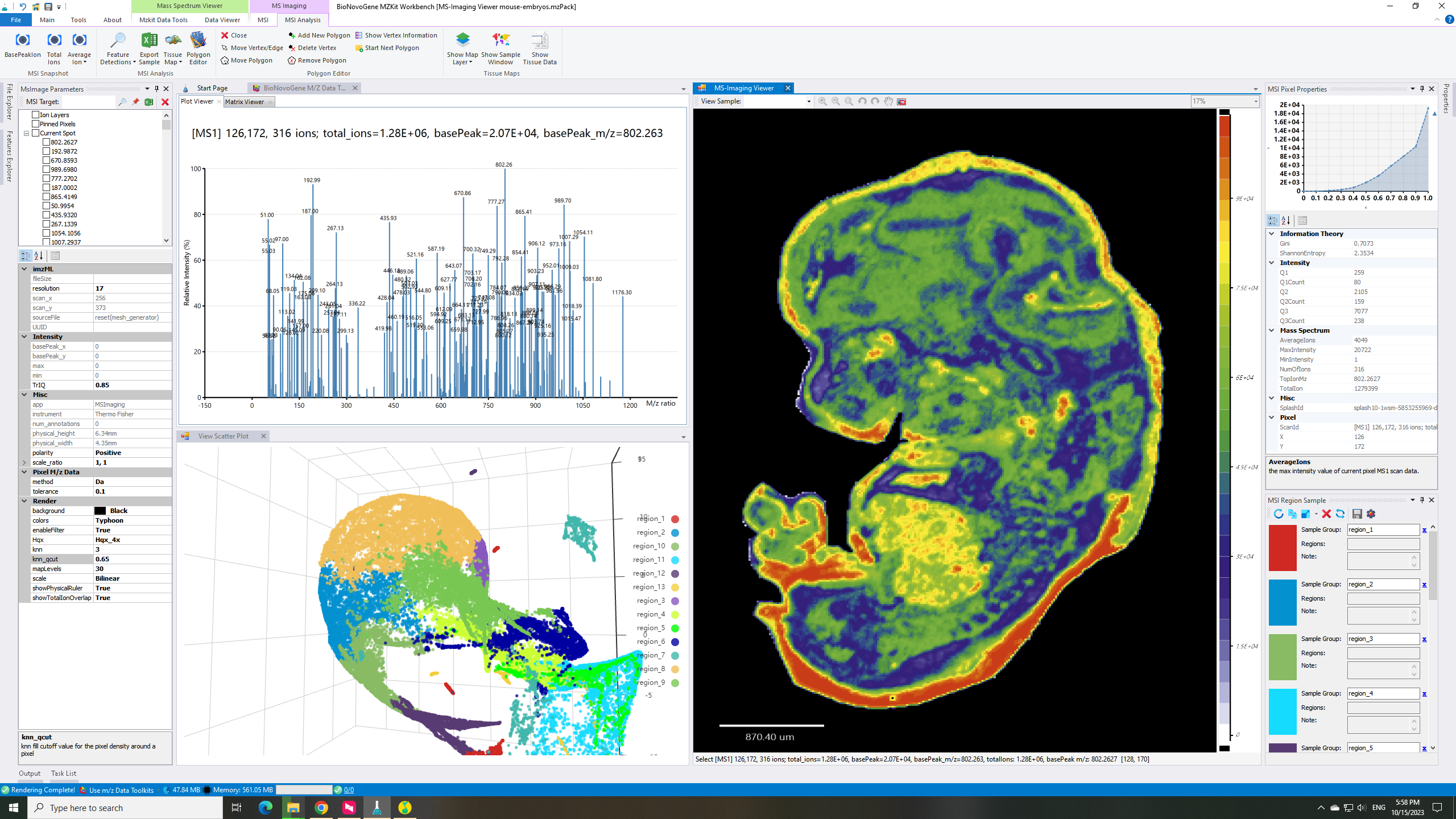
估计阅读时长: 6 分钟大家好呀,今天的这篇文章主要是为了回答在B站上的一位小伙伴的请求 Order by Date Name Attachments render-parameters • 18 kB • 618 click 2023年10月15日view-umap • 427 […]

[…] 对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。 […]
[…] 在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。 […]
😲啊?
谢老师,写快点呀,在看着你更新文章呢。
[…] 最近的工作中我需要按照之前的这篇博客文章《基因组功能注释(EC Number)的向量化嵌入》中所描述的流程,将好几十万个微生物基因组的功能蛋白进行酶编号的比对注释,然后基于注释结果进行向量化嵌入然后进行数据可视化。通过R#脚本对这些微生物基因组的蛋白fasta序列的提取操作,最终得到了一个大约是58GB的蛋白序列。然后将这个比较大型的蛋白序列比对到自己所收集到的ec number注释的蛋白序列参考数据库之上。 […]