
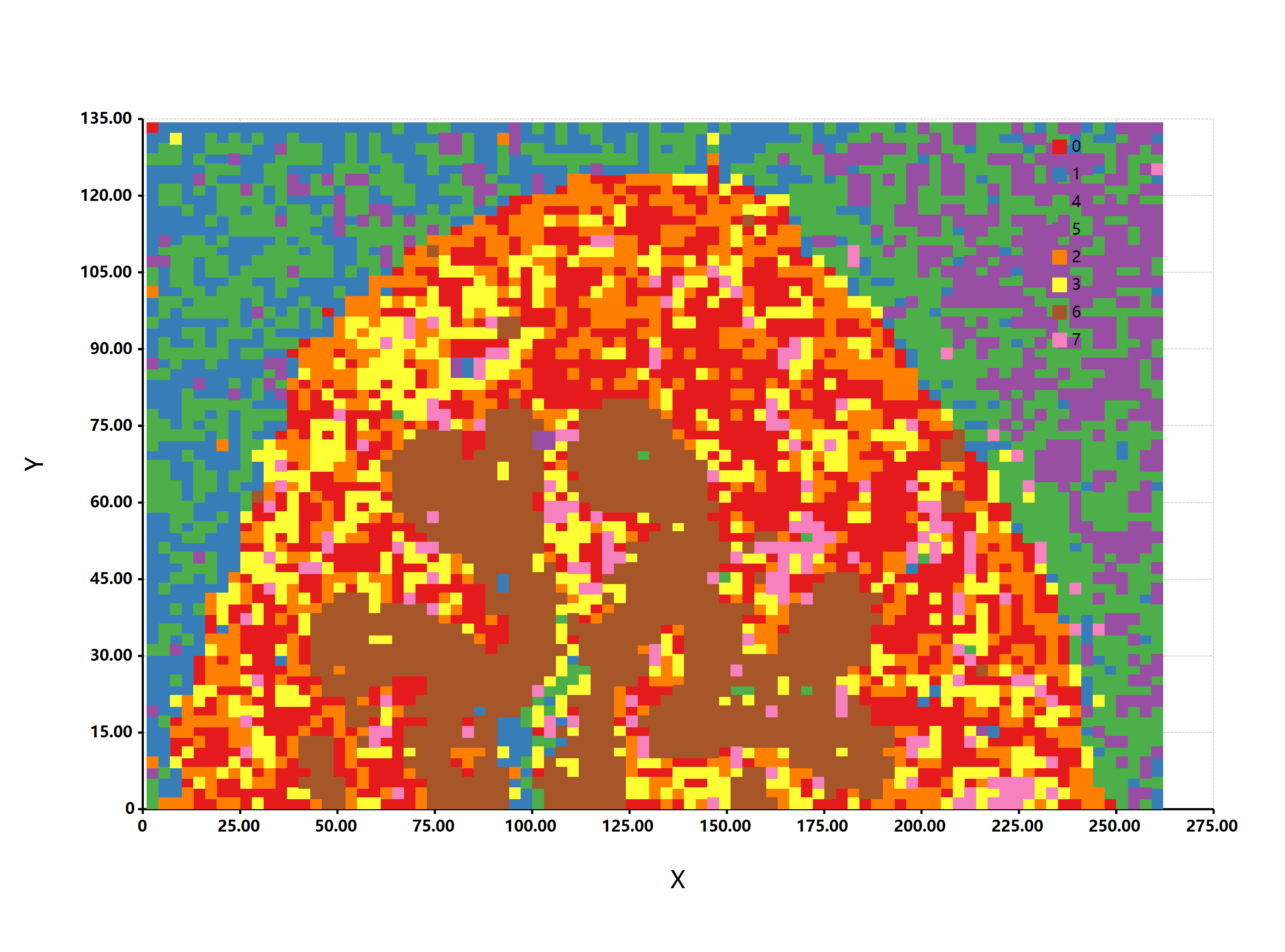
估计阅读时长: 15 分钟https://gcmodeller.org 在这篇博客文章之中,我主要是来详细介绍一下是如何从头开始实现Phenograph单细胞分型算法的。在之前的一篇博客文章《【单细胞组学】PhenoGraph单细胞分型》之中,我们介绍了Phenograph算法的简单原理,以及一个在R语言之中所实现的Phenograph算法的程序包Rphenograph。在这里我主要是详细介绍在GCModeller软件之中所实现的VisualBasic语言版本的Phenograph单细胞分型算法。 Attachments Rphenograph • 236 kB • 664 click 2021年9月20日
估计阅读时长: 11 分钟PhenoGraph提供了与UMAP类似的算法过程进行单细胞组学数据的细胞分型处理操作。与UMAP方法相比,PhenoGraph并不会产生数据降维效果,仅仅产生数据点Cluster信息。如果需要将数据进行可视化,还需要借助于t-SNE算法将PhenoGraph的分型结果数据投影到一个二维平面上完成。 Order by Date Name Attachments Phenograph-image4 • 200 kB • 687 click 2021年8月9日Automated Optimal Parameters […]

[…] 对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。 […]
[…] 在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。 […]
😲啊?
谢老师,写快点呀,在看着你更新文章呢。
[…] 最近的工作中我需要按照之前的这篇博客文章《基因组功能注释(EC Number)的向量化嵌入》中所描述的流程,将好几十万个微生物基因组的功能蛋白进行酶编号的比对注释,然后基于注释结果进行向量化嵌入然后进行数据可视化。通过R#脚本对这些微生物基因组的蛋白fasta序列的提取操作,最终得到了一个大约是58GB的蛋白序列。然后将这个比较大型的蛋白序列比对到自己所收集到的ec number注释的蛋白序列参考数据库之上。 […]