

估计阅读时长: 5 分钟https://github.com/xieguigang/graphQL 构建一个图数据库,可以用来帮我们解决复杂的知识关联计算问题。例如我们想要程序向我们回答dihydrogen oxide与water是否是同一个东西。如果光从字符串比较角度上面来看待这个问题的话,很显然,二者的字符串比较结果肯定是False。面对上面的这个问题,图数据库则可以很简单的向我们回答道上面的两个字符串都是指代的同一个东西。 Order by Date Name Attachments tumblr_inline_mqvdlydGCp1qz4rgp • 124 kB • 620 click 2022年3月5日Capture […]
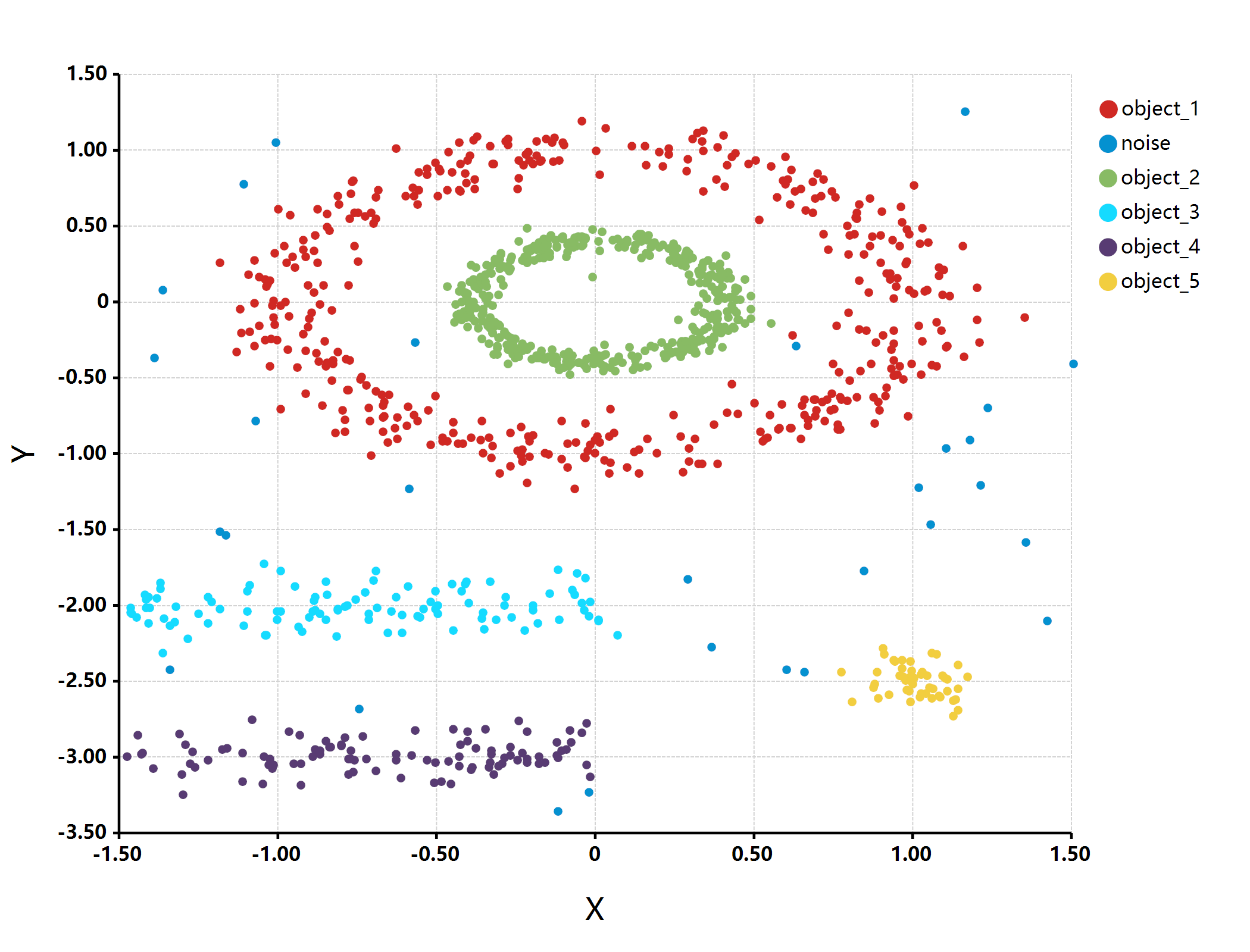
估计阅读时长: 2 分钟imports "clustering" from "MLkit"; require(graphics2D); multishapes = read.csv("./multishapes.csv"); [x, y] = list(multishapes[, "x"], multishapes[, "y"]); print(multishapes, […]

估计阅读时长: < 1 分钟https://github.com/rsharp-lang/R-sharp 前言 经过了2021年一年时间的奋斗,目前R#脚本语言环境终于可以算是能够支撑起比较完整的数据分析流程了。在2021年这段时间,我为R#脚本语言环境大概做了以下几件我认为是比较里程碑式的工作: 建立起了一个比较成熟的脚本打包系统 仿照R语言引入了ggplot和ggraph类似的作图系统 借助于mzkit的开发,将R#语言成功的应用于商业化的质谱数据分析产品之中 为了扩大R#语言环境的受众,在2022年初,也就是这个月内,我相继为Python语言和Julia语言添加了对R#语言环境的支持。下面我们就来聊聊在R#语言环境中的对上面所提到的两种语言的支持。 Order by Date Name Attachments programming • 262 kB […]
估计阅读时长: 18 分钟https://github.com/rsharp-lang/R-sharp/tree/master/studio/RData 如果我们需要将上游的R数据分析环境之中的数据集串流至下游的R#数据分析环境之中,构建出一个不同的数据分析环境混合在一块的自动化数据分析流程。我们一般会需要将上游的R环境之中的数据符号对象以RData的格式串流到下游环境中,下游环境进行反序列化加载数据到环境中执行相应的分析。例如在下游执行定制化程度更高的数据作图,将数据以在上游R环境中比较困难实现的其他二进制文件格式进行保存,或者进行分布式的跨物理机的集群化计算,等等用于实现单纯依靠R环境所比较困难实现的功能。 从上一篇博客文章之中我们比较下详细的了解了RData数据文件的文件格式以及对应的读取操作。在这篇文章之中我们来了解如何基于我们通过对RData文件读取操作所获取得到的链表数据进行反序列化操作,将R环境之中的数据集串流加载到下游的R#数据分析环境之中。 Order by Date Name Attachments rstudio-og-fb-1-1024x538 • 39 kB • 679 click 2021年12月4日read-vector […]
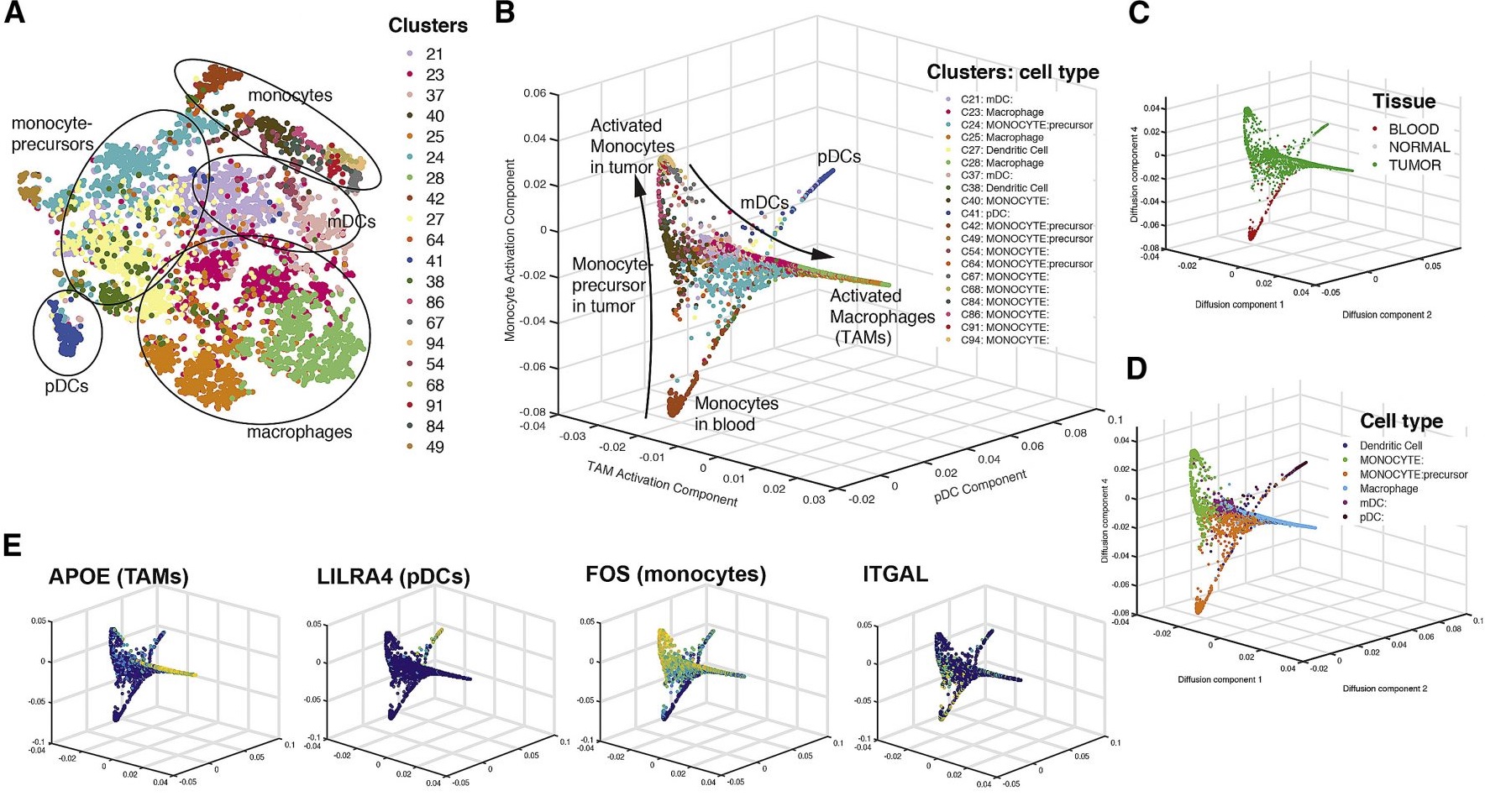
估计阅读时长: 14 分钟https://github.com/rsharp-lang/ggplot 之前在阅读一篇单细胞组学数据分析的文献,觉得在文献之中有一些三维散点图用于展示降维聚类结果的效果非常的好看。于是自己在R#语言之中的ggplot程序包的2D绘图的功能基础之上,进行了三维图形数据可视化功能的开发。 (A) t-SNE map projecting myeloid cells from BC1-8 patients (all tissues). Cells are colored […]
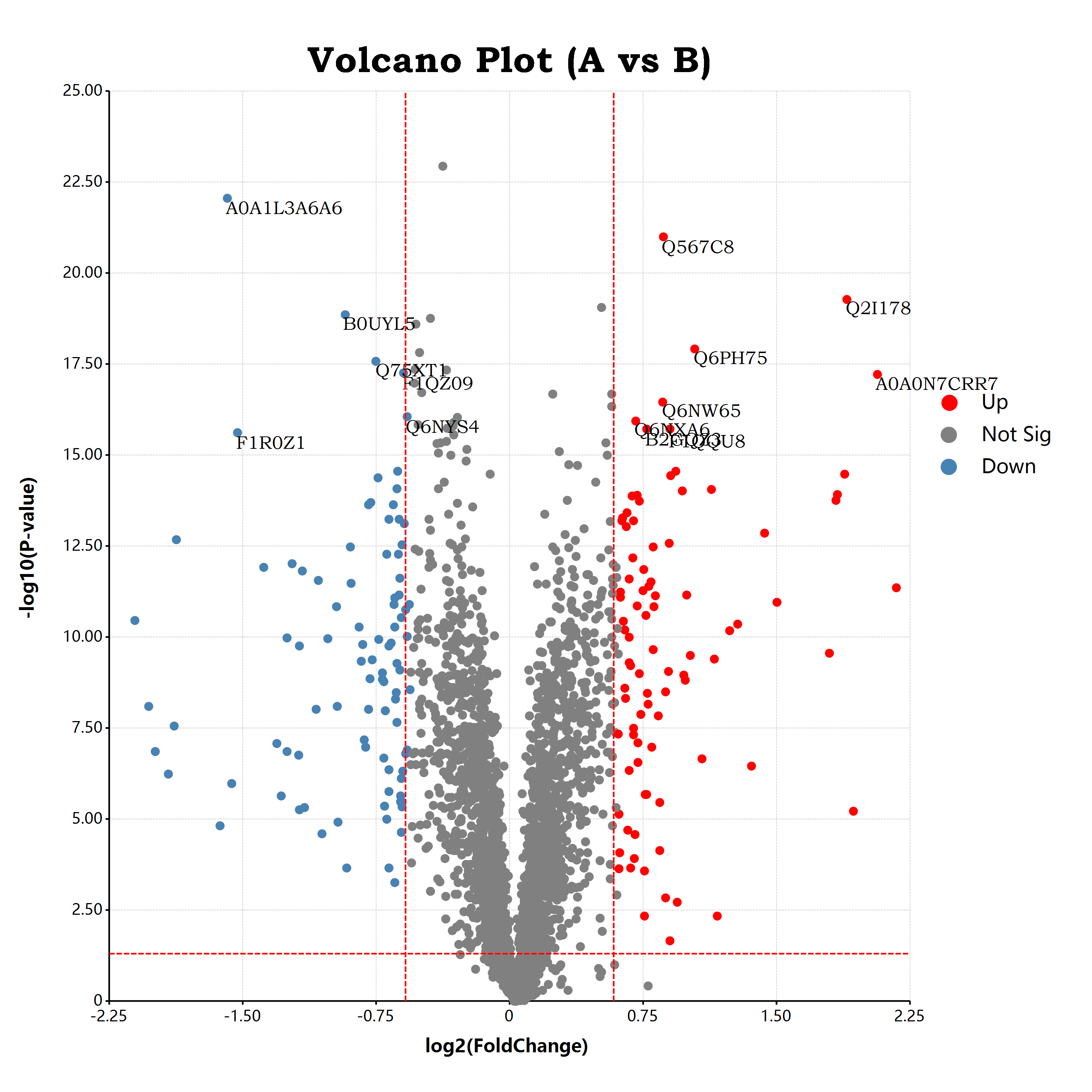
估计阅读时长: 17 分钟https://github.com/rsharp-lang/ggplot 接上一篇博客文章中谈到,我们已经通过R#语言之中的ggplot程序包绘制出了一个可以使用的火山图。在这里,我们将会通过在火山图上添加更多的可视化元素来为大家介绍R#语言之中的ggplot程序包的进阶使用方式。 Order by Date Name Attachments volcano • 651 kB • 736 click 2021年10月9日volcano • […]

估计阅读时长: 10 分钟Ascii art是一种使用连续排列的ascii字符进行图形设计的技术。它可以显示在任意的文本框中。ascii art出现于上世纪70年代,最初是当时电脑显示技术不发达时用于显示简单图像的一种娱乐。后来逐渐流行开来,有了专门以此为兴趣的艺术家和研究者。 Order by Date Name Attachments 1537192287563 • 50 kB • 719 click 2021年10月1日ASCII-bilibili […]
估计阅读时长: 17 分钟https://github.com/xieguigang/sciBASIC/tree/master/gr/Microsoft.VisualBasic.Imaging/Drawing3D 因为大家大多数都是从小接受电子游戏,所以长大了之后能够自己从零开始开发一个完整的3维图形引擎是每一个男程序员的梦想。这个就像玩机械的男人的梦想就是自己从头开始组装一辆汽车。还好这个梦想我在几年前就已经实现了。 Order by Date Name Attachments Cube3D_VB.NET • 4 MB • 745 click 2021年9月19日Cube_screenshot • […]
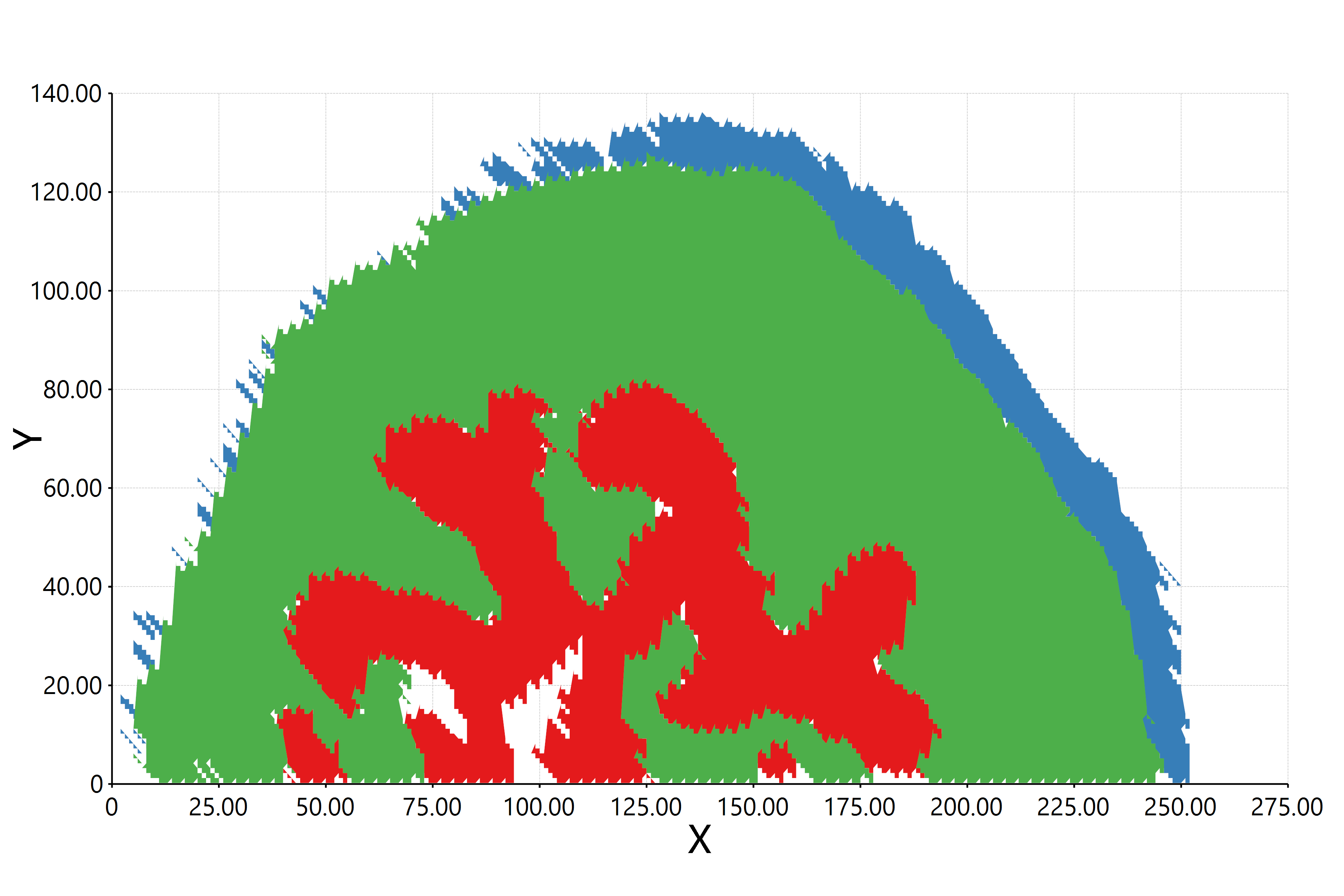
估计阅读时长: 11 分钟https://github.com/xieguigang/sciBASIC 最近在研究实现空间代谢组学中的一些特征区域的自动化划分分割。在得到了特征点集合之后,我们需要根据一些图像处理算法进行特征区域的提取操作。之前,我们尝试过基于绘制等高线图Marching Squares算法的方式来将特征点集合自动转换为特征区域的多边形,实现轮廓扫描获取的功能。但是实现的效果嘛,和实际的区域存在着一些较大的差异。 Order by Date Name Attachments HR2MSI mouse urinary bladder S096 - spatial regions […]
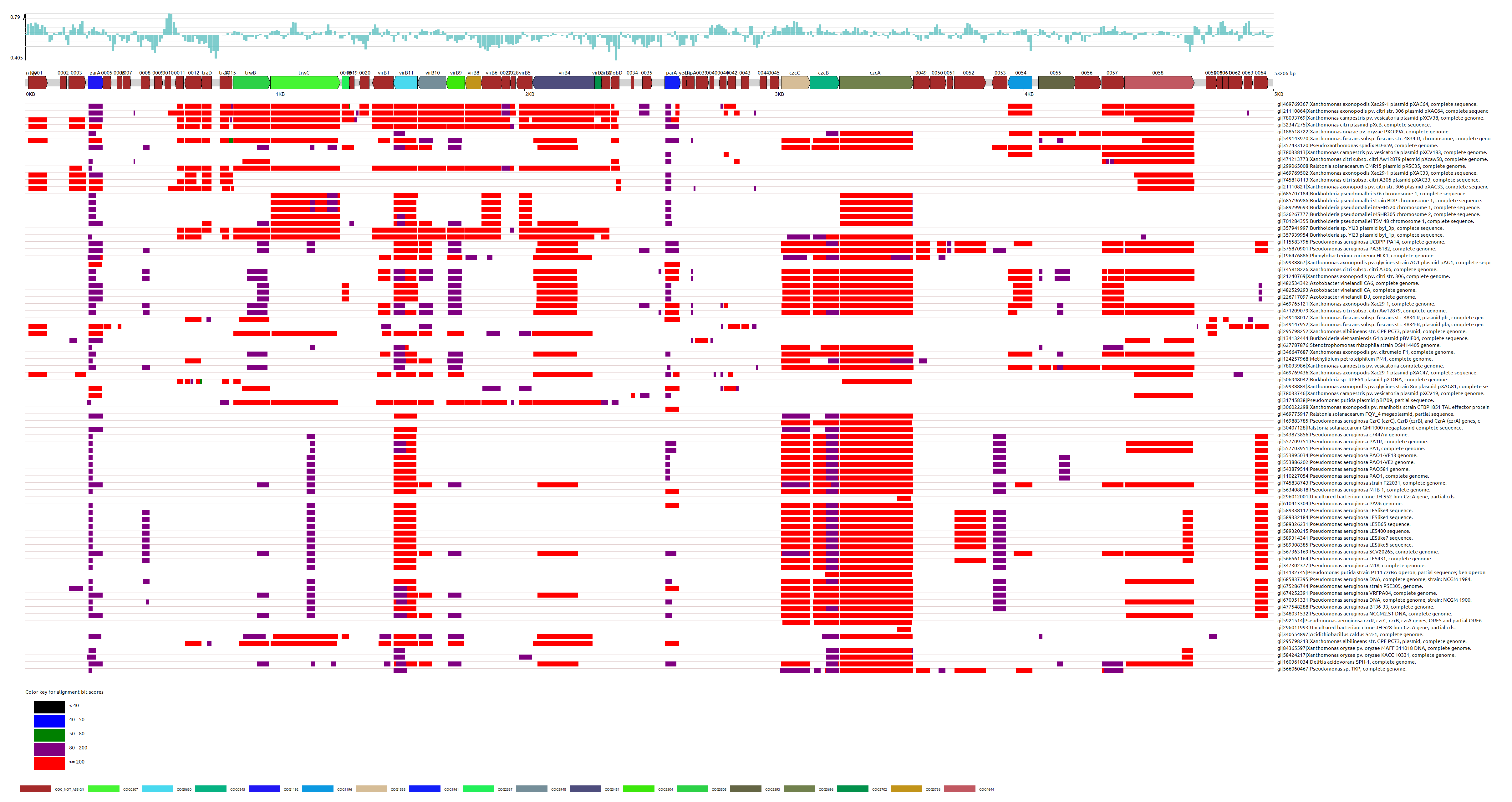
估计阅读时长: 14 分钟在基因组学研究中,将新测序的基因或者针对目标基因组进行基于KEGG代谢通路体系的虚拟细胞建模,都会需要将目标基因组与已知功能基因进行比对注释。KEGG(Kyoto Encyclopedia of Genes and Genomes)数据库通过其KEGG Orthology (KO)系统,为基因功能注释提供了一个强大的平台。KO系统将功能上保守的直系同源基因归为一类,每个KO条目(K编号)代表一个直系同源基因群,这些基因在不同物种中通常执行相似的生物学功能。因此,将新基因的序列与KEGG数据库中的已知基因进行比对,可以推断其可能的KO编号,从而将其功能映射到KEGG通路图或功能层级中。 Order by Date Name Attachments kegg_overview • 313 […]

[…] 对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。 […]
[…] 在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。 […]
😲啊?
谢老师,写快点呀,在看着你更新文章呢。
[…] 最近的工作中我需要按照之前的这篇博客文章《基因组功能注释(EC Number)的向量化嵌入》中所描述的流程,将好几十万个微生物基因组的功能蛋白进行酶编号的比对注释,然后基于注释结果进行向量化嵌入然后进行数据可视化。通过R#脚本对这些微生物基因组的蛋白fasta序列的提取操作,最终得到了一个大约是58GB的蛋白序列。然后将这个比较大型的蛋白序列比对到自己所收集到的ec number注释的蛋白序列参考数据库之上。 […]